Johnson & Bhattacharyya (1992), Weiss (1999) and Freund (2001)
Statistik deskriptif menunjukkan karakteristik data yang kita kumpulkan. Jika kita mengamati klasemen sementara liga utama inggris, kita dapat melihat perolehan nilai, goal, kekalahan, draw, serta goal yang telah dicetak masing-masing klub di liga tersebut. Dengan demikian kita akan mengetahui tim mana yang paling produktif, yang paling banyak draw, rekor kandang, tandang dan sebagainya. Penyajian tabel inilah yang dapat kita sebut sebagai penyajian data secara deskriptif.
Data Sampel dan Data Populasi
Data populasi adalah seluruh bagian dari kelompok data, seperti data berat bayi yang lahir di Indonesia pada tahun 2010, atau berat semen yang diproduksi oleh pabrik per zak.
Parameter
Jumlah yang menjelaskan populasi disebut sebagai parameter dan biasanya dinyatakan dalam huruf Yunani, sedangkan angka yang digunakan untuk menjelaskan kelompok data sampel disebut statistik.
Frekuensi (F)
Biasanya dinyatakan dengan persentase, bentuk yang tepat dalam menampilkan data frekuensi adalah diagram dan grafik.
Pada sampel di bawah ini kita lihat data perolehan suara pada pemilihan walikota kota A, dengan jumlah suara yang diperoleh bapak Mamat memimpin dengan 38,89%.
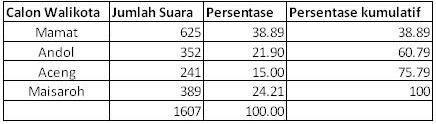
Data ini akan lebih menarik jika disajikan dalam bentuk diagram batang (bar chart) distribusi frekuensi suara pada pemilihan walikota kota A.

Atau dalam bentuk diagram kue (pie chart) seperti gambar di bawah ini;

Mode dan Median
Mode adalah nilai yang paling sering muncul, ia menyatakan jumlah kategori yang paling sering muncul pada suatu kasus. Ketika anda membagikan kuesioner kepada karyawan kantor untuk memilih apa yang paling suka mereka lakukan di waktu luang, jika sebagian besar menjawab mendengarkan musik, maka mendengarkan musik adalah mode. Mode cocok untuk diterapkan pada data yang bersifat nominal.
Median adalah nilai tengah, ia merupakan titik tengah pembagi data. Contoh berikut dapat mendeskripsikan median yang biasa digunakan untuk data-data ordinal.

Mean (M)
Mean merupakan rataan dari skor yang diukur, menghitung mean untuk variable X dapat menggunakan rumus:

Fosfat yang dihasilkan dari limbah deterjen merk A, B, C, D, dan E adalah berturut-turut 43, 42, 31,32,37, hitunglah mean;

Variabilitas/Dispersi
Salah satu teknik untuk mengelompokkan data pada teknik statistik deskriptif adalah menghitung dispersi atau variabilitas. Tiga cara menghitung variabilitas antara lain:

Contoh perhitungan keragaman dan standar deviasi dapat kita lihat di bawah ini:
*** berikut ini diberikan data hasil ujian statistik dasar untuk 10 mahasiswa di perguruan tinggi LOLipop dengan data yang diberikan sebagai berikut:

*** Menghitung Nilai Rataan:

*** Menghitung Keragaman (variance):

***Menghitung Standar Deviasi:


Standar Error (Sε)
Standar error merupakan variabilitas distribusi sampling dalam statistik. Standar eror dinyatakan dengan rumus:

dimana:
Se = standar eror
S = standar deviasi
N = jumlah sampel
***jika diketahui standar deviasi = 4, dan jumlah sampel yang digunakan adalah 30, maka standar eror adalah;

Selang Kepercayaan (CI)
Selang kepercayaan memberikan batas bawah dan batas atas statistik pada kemungkinan tertentu yang ditentukan oleh peneliti. Tingkat kepercayaan yang biasa digunakan adalah 90%, 95%, dan 99%. Seorang peneliti akan menentukan tingkat kepercayaan dan jumlah sampel yang akan menentukan batas bawah dan batas atas CI yang digunakan.
CI = Mean + (standar eror x tingkat kepercayaan)
***jika diketahui jumlah sampel (n) adalah 30, standar eror (Se) adalah 0,73, sedangkan mean adalah 50, hitung selang kepercayaan pada taraf nyata 5%.
CI = 50 + (0,73 x 2,045)
Maka CI = 50 + (1,5)
Sebaran Sampel dan Populasi
Sebaran frekuensi dari suatu variabel menggunakan
populasi dan sampel populasi sebagai indikatornya. Sebaran sampel adalah
gambaran kecil mengenai sebaran populasi. Semakin banyak sampel yang digunakan,
maka frekuensi relatif sampel pada setiap kelas interval akan semakin mendekati
frekuensi relatif populasi yang sebenarnya, dengan demikian sebaran sampel akan
semakin jelas menggambarkan sebaran populasi.
Pada variabel kontinyu, kita dapat memilih interval
kelas pada sebaran frekuensi dan grafik bentuk histogram. Namun ketika sampel
bertambah maka interval kelas secara langsung juga akan bertambah, maka
histogram sampel akan mendekat pola kurva
simetris (kurva sebaran). Kurva yang kita dapatkan tersebut dapat
digunakan untuk mewakili sebaran populasi. Pada gambar di bawah ini ditunjukkan
dua contoh histogram dengan populasi kecil dan populasi besar, dan kurva
sebaran yang menggambarkan sebaran populasinya.


Metode dalam menerangkan sebaran populasi sampel
adalah dengan melihat bentuk kurva sebaran. Kelompok sebaran dengan bentuk
kurva seperti lonceng akan berbeda dengan kelompok sebaran dengan bentuk kurva
U. kurva sebaran lonceng dan U mengindikasikan bentuk yang simetris, Sedangkan
sebaran yang tidak simetris dikatakan menjulur ke arah kanan atau ke arah kiri,
dimana salah satu sisinya lebih panjang daripada sisi yang lain seperti gambar berikut ini:

download versi pdf di bawah ini >>>
Beli Buku referensi lengkap








0 komentar:
Posting Komentar